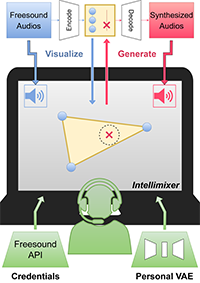
This paper presents a non-backend web architecture for generative audio mixing from the Freesound website using a Variational Autoencoder. It is designed to experiment with the nonexisting audios in large audio databases without the need to populate them. It works directly from the browser using JavaScript tools with a serverless approach and relies exclusively on the computational capacity of the client. The platform's Graphical User Interface allows rapid sampling of the autoencoder sound space and is under active development while the logic is finalized. A Variational Autoencoder has been trained to serve as the default model. Users can upload their own to operate independently. The platform aims to provide users with a straightforward and quick-access interface to generative sounds, supporting the audiovisual industry by filling the existing gaps in audio repositories with synthetic media.
Click to purchase paper as a non-member or you can login as an AES member to see more options.
No AES members have commented on this paper yet.
![]() To be notified of new comments on this paper you can
subscribe to this RSS feed.
Forum users should login to see additional options.
To be notified of new comments on this paper you can
subscribe to this RSS feed.
Forum users should login to see additional options.
If you are not yet an AES member and have something important to say about this paper then we urge you to join the AES today and make your voice heard. You can join online today by clicking here.
