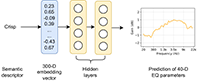
In recent years, machine learning has been widely adopted to automate the audio mixing process. Automatic mixing systems have been applied to various audio effects such as gain adjustment, equalization, and reverberation. These systems can be controlled through visual interfaces, audio examples being provided, usage of knobs, and semantic descriptors. Using semantic descriptors or textual information to control these systems is an effective way for artists to communicate their creative goals. In this paper, the novel idea of using word embeddings to represent semantic descriptors is explored. Word embeddings are generally obtained by training neural networks on large corpora of written text. These embeddings serve as the input layer of the neural network to create a translation from words to equalizer (EQ) settings. Using this technique, the machine learning model can also generate EQ settings for semantic descriptors that it has not seen before. The EQ settings of humans are compared with the predictions of the neural network to evaluate the quality of predictions. The results showed that the embedding layer enables the neural network to understand semantic descriptors. It was observed that the models with embedding layers perform better than those without embedding layers but still not as well as human labels.
Open
Access
Download Now (830 KB)
This paper is Open Access which means you can download it for free.
No AES members have commented on this paper yet.
![]() To be notified of new comments on this paper you can
subscribe to this RSS feed.
Forum users should login to see additional options.
To be notified of new comments on this paper you can
subscribe to this RSS feed.
Forum users should login to see additional options.
If you are not yet an AES member and have something important to say about this paper then we urge you to join the AES today and make your voice heard. You can join online today by clicking here.