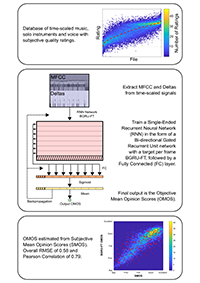
Objective evaluation of audio processed with Time-Scale Modification (TSM) has recently seen improvement with a labeled time-scaled audio dataset used to train an objective measure. This double-ended measure was an extension of Perceptual Evaluation of Audio Quality and required reference and test signals. In this paper two single-ended objective quality measures for time-scaled audio are proposed that do not require a reference signal. Internal representations of spectrogram and speech features are learned by either a Convolutional Neural Network (CNN) or a Bidirectional Gated Recurrent Unit (BGRU) network and fed to a fully connected network to predict Subjective Mean Opinion Scores. The proposed CNN and BGRU measures respectively achieve average Root Mean Square Errors of 0.61 and 0.58 and mean Pearson Correlation Coefficients of 0.77 and 0.79 to the time-scaled audio dataset. The proposed measures are used to evaluate TSM algorithms and comparisons are provided for 15 TSM implementations. A link to implementations of the objective measures is provided.
Click to purchase paper as a non-member or you can login as an AES member to see more options.
No AES members have commented on this paper yet.
![]() To be notified of new comments on this paper you can
subscribe to this RSS feed.
Forum users should login to see additional options.
To be notified of new comments on this paper you can
subscribe to this RSS feed.
Forum users should login to see additional options.
If you are not yet an AES member and have something important to say about this paper then we urge you to join the AES today and make your voice heard. You can join online today by clicking here.
